
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
Tags
- MSSQL INDEX
- 테이블용량조회
- MSSQL
- jtds
- jdbc
- mssql bulk insert
- select count
- solvesql
- annotation
- SQLite
- 포인터
- 윈도우함수
- jdbc bulk insert
- mssql 대용량 데이터 insert
- SQL
- 자바 어노테이션
- mssql insert
- SQL Server
- MS-SQL
- MSSQL 인덱스
- Java
- 어노테이션
- 자바
- sql index
- sql insert
- c#
- C++
- mssql 대용량 데이터
- lag
Archives
- Today
- Total
Basic Byte Bites
SQL 행의 개수 구하기 COUNT(*) vs sys.sysindexes 본문
일반적으로 행의 개수를 구할때 COUNT(*)을 사용하는 경우가 많다. 그러나 테이블을 스캔하여 ROW수를 반환하기 때문에 큰 테이블에는 시간이 오래걸린다. 하여 큰 테이블의 경우 COUNT(*)대신 sys.sysindexes뷰를 사용하여 ROWS 컬럼을 반환하는것이 좋음!

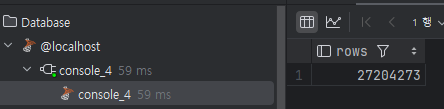
SELECT COUNT(*) FROM 테이블명
위 대신 아래 쿼리를 사용한다.
SELECT rows FROM sys.sysindexes WHERE id = object_id('테이블명') and indid < 2
indid < 2 조건절을 사용하는 이유?
- INDID값이 0은 클러스터링(쉽게말해 Primary Key)이 없는 테이블일 경우, 1은 클러스터링 인덱스인 경우, 2이상은 비클러스터드 인덱스이며, 테이블의 행 수를 포함하지 않음
'DataBase > MS_SQL' 카테고리의 다른 글
| [MS-SQL, SQL Server] 비효율적인(사용량이 적은) 인덱스 찾기 (0) | 2025.02.25 |
|---|---|
| MS-SQL 테이블 용량 조회 쿼리 (+ 간단한 설명) (0) | 2024.07.31 |
'DataBase/MS_SQL' Related Articles
more
